Claude Opus 4.6: Complete Guide — 1M Context, Adaptive Thinking & Benchmarks (2026)
By Learnia Team
Claude Opus 4.6: Complete Guide — 1M Context, Adaptive Thinking & Benchmarks (2026)
This article is written in English. Our training modules are available in multiple languages.
📅 Last Updated: February 6, 2026 — Released February 5, 2026.
📚 Related: Claude Opus 4.5 Guide | Claude Cowork Guide | Opus 4.6 vs GPT-5.3 Codex | LLM Benchmarks 2026
📺 Official Announcement Video
Source: Anthropic YouTube — Official announcement, February 5, 2026.
Table of Contents
- →What Is Claude Opus 4.6?
- →Technical Specifications
- →What's New vs. Opus 4.5
- →Benchmark Performance
- →Key Features Deep Dive
- →Pricing & Availability
- →How to Use Opus 4.6
- →Use Cases & Recommendations
- →Safety & Alignment
- →FAQ
On February 5, 2026, Anthropic released Claude Opus 4.6, their most capable AI model to date. Opus 4.6 represents a qualitative leap in three critical areas: it introduces a 1 million token context window (the first Opus-class model with this capability), adaptive thinking that autonomously adjusts reasoning depth, and state-of-the-art agentic coding performance that outperforms every competitor on Terminal-Bench 2.0.
This isn't an incremental update. Opus 4.6 redefines what's possible with long-context AI: its MRCR v2 score of 76% on 8-needle 1M retrieval dwarfs Sonnet 4.5's 18.5%, meaning it can genuinely work with massive documents, codebases, and research corpora without losing information. Combined with a 67% price reduction on input tokens compared to Opus 4.5, this model makes frontier capabilities accessible at a fraction of the previous cost.
In this comprehensive guide, we'll break down Opus 4.6's architecture, benchmark results, new features, pricing, and practical use cases — everything you need to decide if and how to integrate it into your workflow.
What Is Claude Opus 4.6?
Claude Opus 4.6 is Anthropic's flagship AI model, designed for the most demanding tasks in coding, reasoning, analysis, and knowledge work. It is the successor to Claude Opus 4.5, released three months earlier, and represents Anthropic's most significant model upgrade of the 2025-2026 cycle.
Key definition: Claude Opus 4.6 is a frontier large language model with a 1M token context window, adaptive reasoning, and the highest scores on agentic coding and long-context retrieval benchmarks as of February 2026. It is available via API, Claude.ai, AWS Bedrock, and Google Vertex AI.
What Makes Opus 4.6 Different?
Unlike traditional models that treat every query with the same reasoning depth, Opus 4.6 introduces adaptive thinking — the model itself decides when a problem requires deep chain-of-thought reasoning and when a quick response suffices. This eliminates the need for users to manually set "thinking effort" levels, producing faster responses for simple tasks and deeper analysis for complex ones.
Technical Specifications
| Specification | Claude Opus 4.6 | Claude Opus 4.5 (previous) |
|---|---|---|
| Model ID | claude-opus-4-6 | claude-opus-4-5-20250929 |
| Context Window | 1M tokens (beta) / 200K standard | 200K tokens |
| Max Output | 128K tokens | 32K tokens |
| Extended Thinking | ✅ Yes | ✅ Yes |
| Adaptive Thinking | ✅ New | ❌ No |
| Effort Levels | low, medium, high (default), max | low, medium, high |
| Knowledge Cutoff | May 2025 (reliable) / Aug 2025 (training) | March 2025 |
| Input Price | $5 / M tokens | $15 / M tokens |
| Output Price | $25 / M tokens | $75 / M tokens |
| 1M Context Price | $10 / $37.50 (input/output) | N/A |
The pricing change is dramatic: input tokens are 67% cheaper and output tokens are 67% cheaper than Opus 4.5. This makes Opus 4.6 the most cost-effective frontier model Anthropic has ever released.
What's New vs. Opus 4.5
1. 1 Million Token Context Window (Beta)
Opus 4.6 is the first Opus-class model to support 1M tokens of context. Previous Opus models were capped at 200K. This beta feature activates automatically for prompts exceeding 200K tokens, with slightly elevated pricing ($10/$37.50 per million).
Why it matters: With 1M tokens, you can feed Opus 4.6 an entire codebase (~50,000 lines), a full legal contract set, or hundreds of research papers in a single prompt — and it will actually retain and use that information. The MRCR v2 benchmark proves this isn't just theoretical capacity.
2. Adaptive Thinking
Previous models required users to specify thinking effort (low/medium/high). Opus 4.6 introduces a new paradigm: the model autonomously decides when deeper reasoning helps.
How it works:
- →Simple factual queries → minimal internal reasoning → fast response
- →Complex coding or analysis → deep chain-of-thought → thorough response
- →Ambiguous problems → calibrated reasoning → balanced response
You can still override with manual effort levels, but the adaptive default is highly effective. The max effort level is new and pushes reasoning depth beyond what high offered in Opus 4.5.
3. Context Compaction (Beta)
For long-running agentic sessions, Opus 4.6 can automatically summarize older context to extend task duration without hitting context limits. This is critical for coding agents that need to work on projects over hours, not minutes.
4. Agent Teams (Research Preview)
Multiple Claude Code agents can now work in parallel on the same codebase, each handling independent subtasks. Think of it as parallelized pair programming — one agent handles frontend, another backend, a third writes tests.
5. Massive Price Reduction
| Metric | Opus 4.5 | Opus 4.6 | Change |
|---|---|---|---|
| Input | $15/M | $5/M | -67% |
| Output | $75/M | $25/M | -67% |
This makes Opus 4.6 cheaper than many mid-tier models while delivering frontier performance.
Benchmark Performance
Opus 4.6 delivers state-of-the-art results across multiple benchmarks. Here are the verified scores:
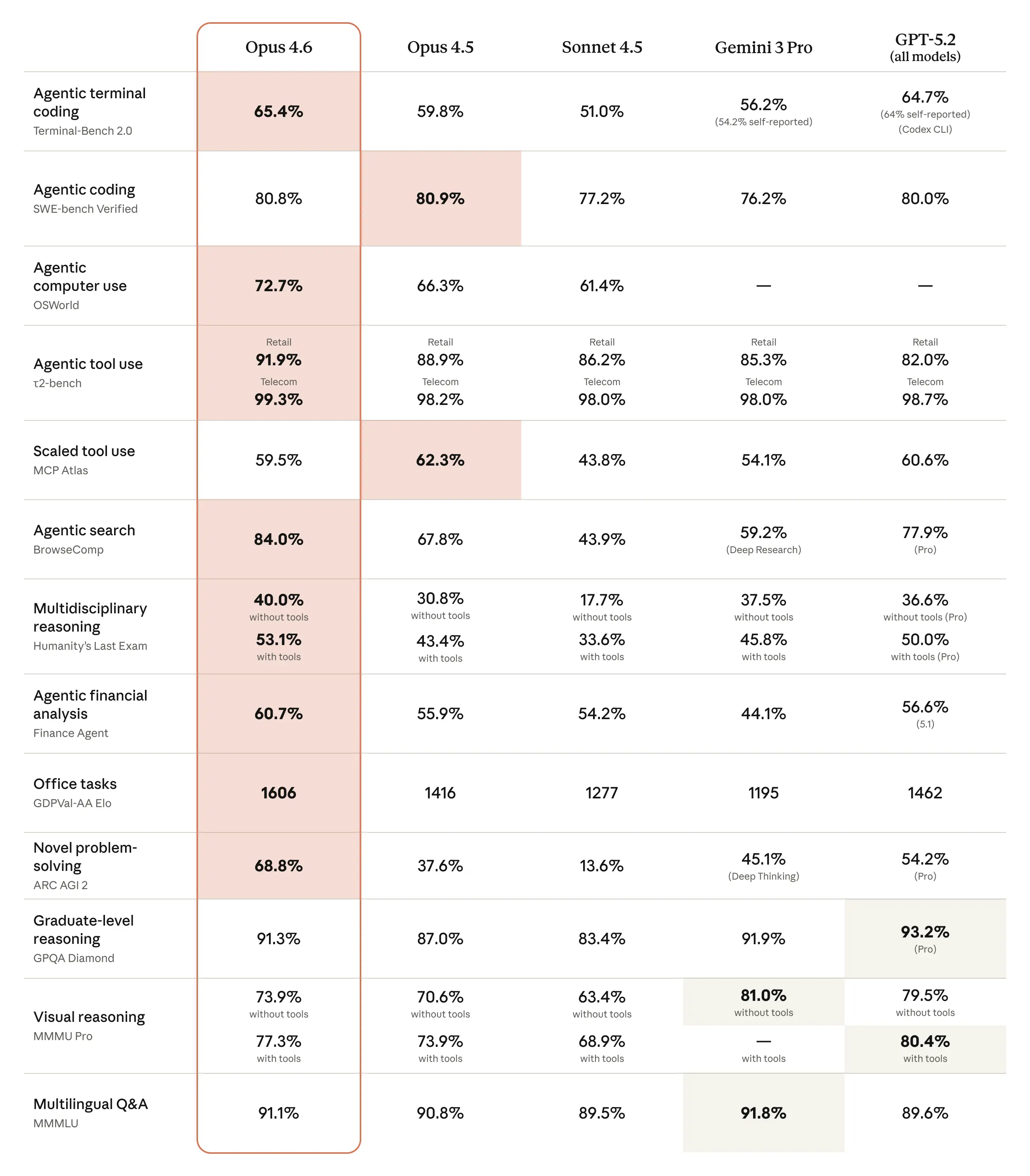 Claude Opus 4.6 benchmark comparison table — Source: Anthropic
Claude Opus 4.6 benchmark comparison table — Source: Anthropic
Agentic Coding
Terminal-Bench 2.0: #1 — Highest score of any model (agentic coding evaluation)
SWE-bench Verified: 81.42% (with prompt modification) — up from Opus 4.5's 80.9%
MCP Atlas (max effort): 62.7% — industry-leading
Opus 4.6 doesn't just generate code — it plans, executes, debugs, and iterates across complex multi-file projects more reliably than any competitor.
Long-Context Retrieval
MRCR v2 (8-needle, 1M variant):
- →Claude Opus 4.6: 76%
- →Claude Sonnet 4.5: 18.5%
This is a qualitative shift, not just an improvement. At 76%, Opus 4.6 can reliably find and use information buried anywhere in a million-token context. Sonnet 4.5's 18.5% means it essentially loses most information in long contexts.
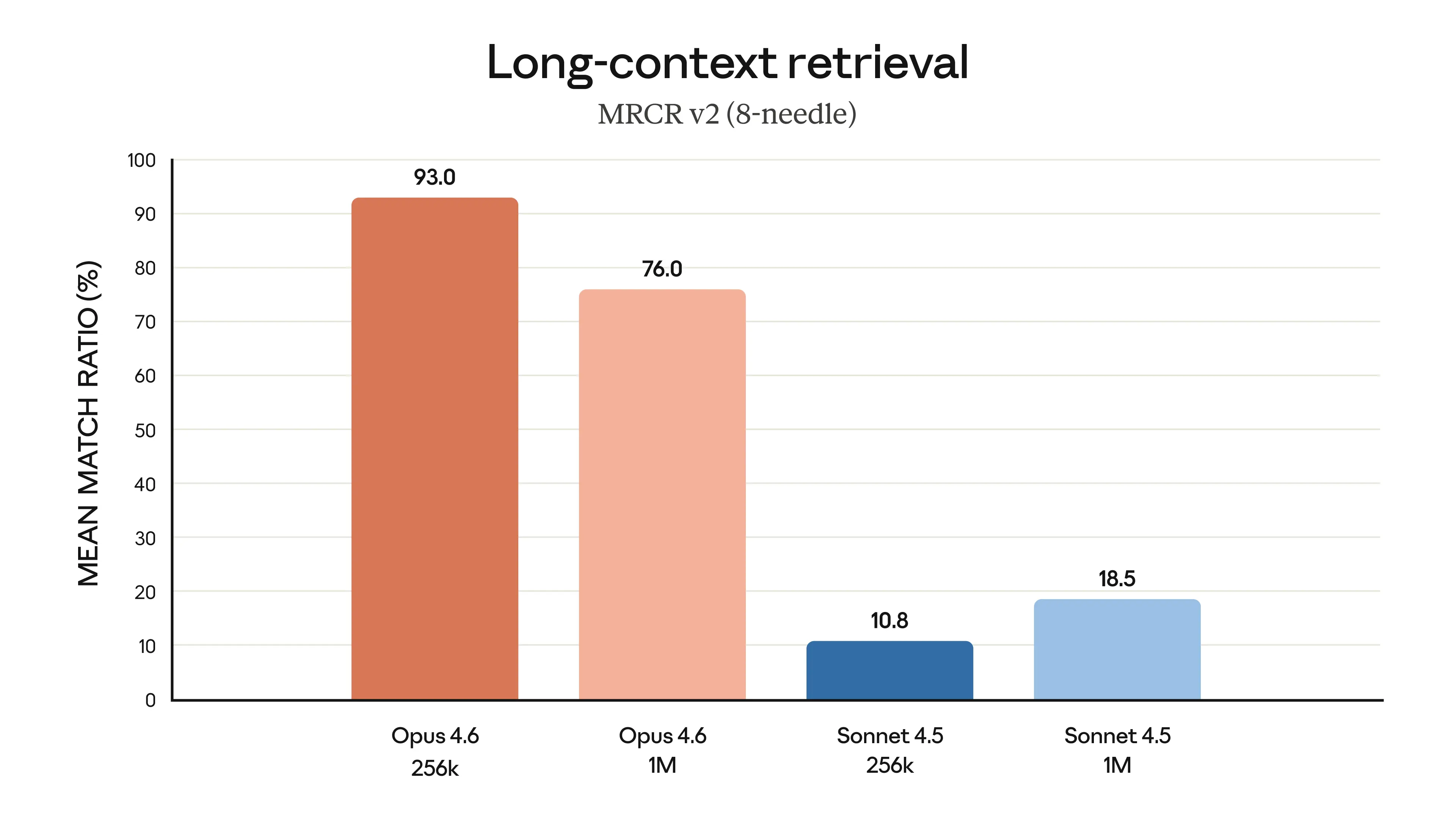 Opus 4.6 shows significant improvement in long-context retrieval — Source: Anthropic
Opus 4.6 shows significant improvement in long-context retrieval — Source: Anthropic
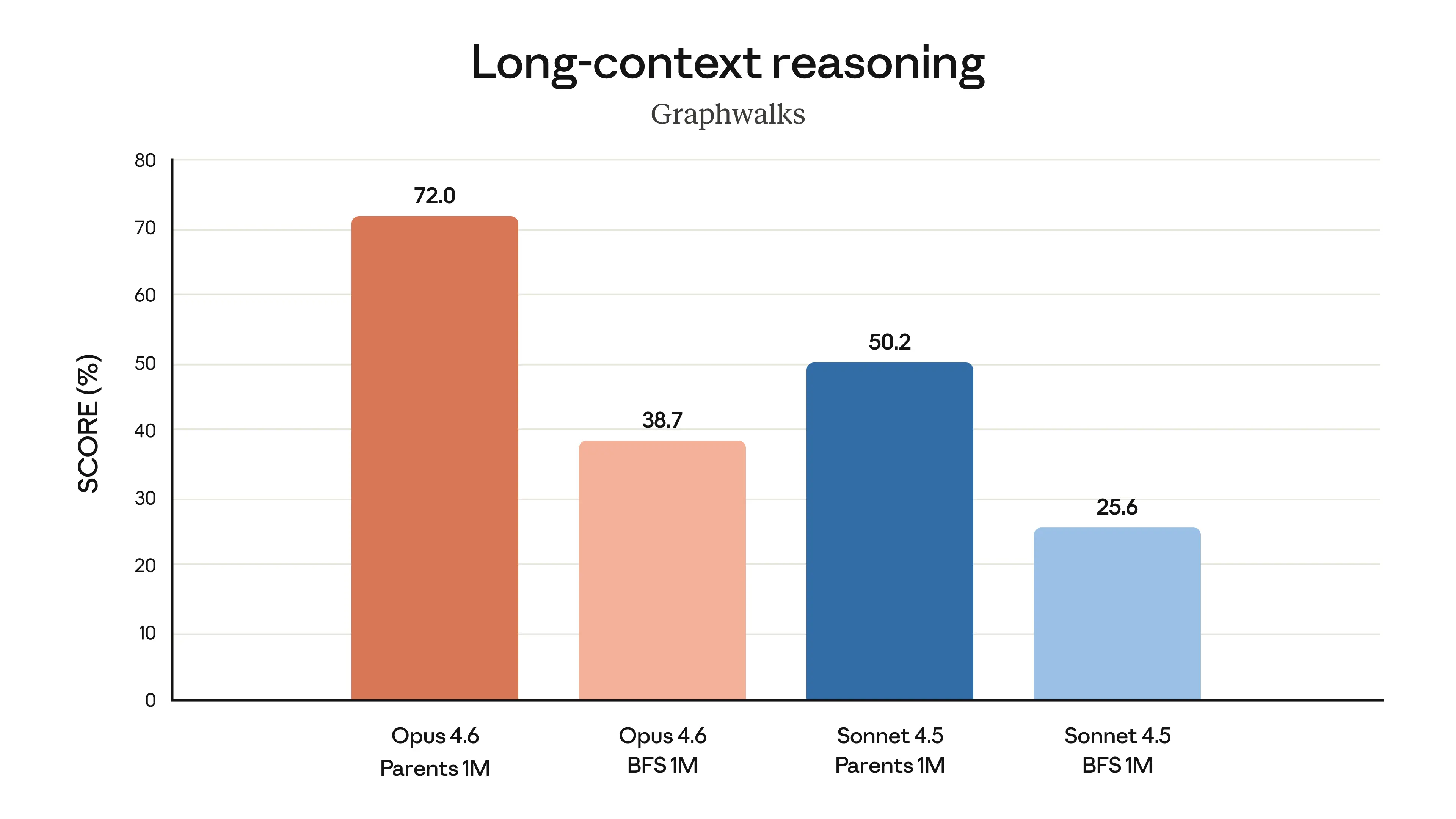 Opus 4.6 excels at deep reasoning across long contexts — Source: Anthropic
Opus 4.6 excels at deep reasoning across long contexts — Source: Anthropic
Complex Reasoning
Humanity's Last Exam: Leads all frontier models — the hardest multidisciplinary reasoning benchmark available.
GDPval-AA (real-world work tasks): Outperforms GPT-5.2 by ~144 Elo points and Opus 4.5 by 190 Elo points.
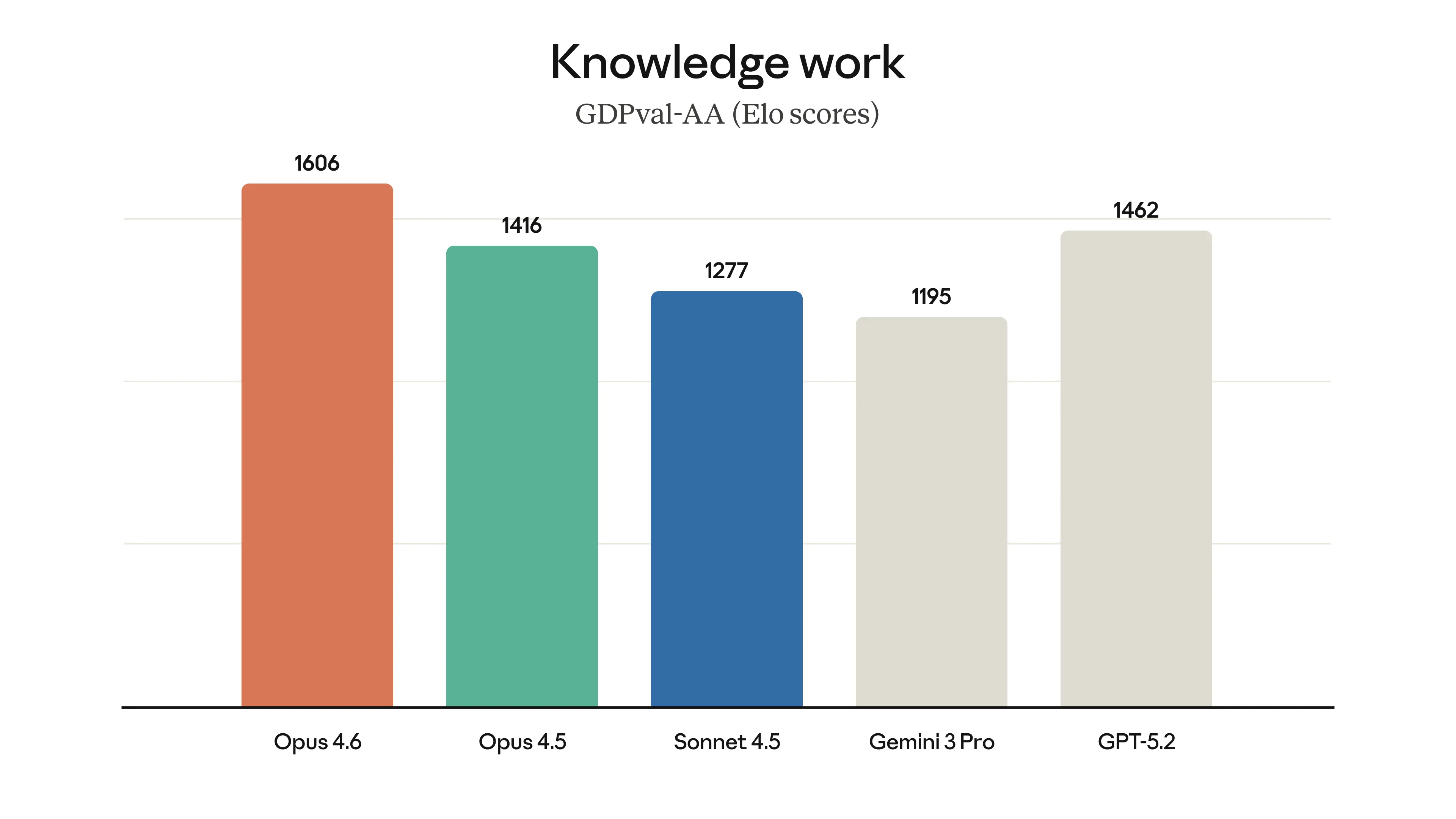 Opus 4.6 is state-of-the-art on real-world work tasks across several professional domains — Source: Anthropic
Opus 4.6 is state-of-the-art on real-world work tasks across several professional domains — Source: Anthropic
Information Retrieval
BrowseComp: Best of any model for finding hard-to-find information online.
- →Multi-agent harness score: 86.8%
Specialized Domains
Cybersecurity (NBIM eval): Won 38 of 40 cybersecurity investigations in blind ranking against Claude 4.5 models.
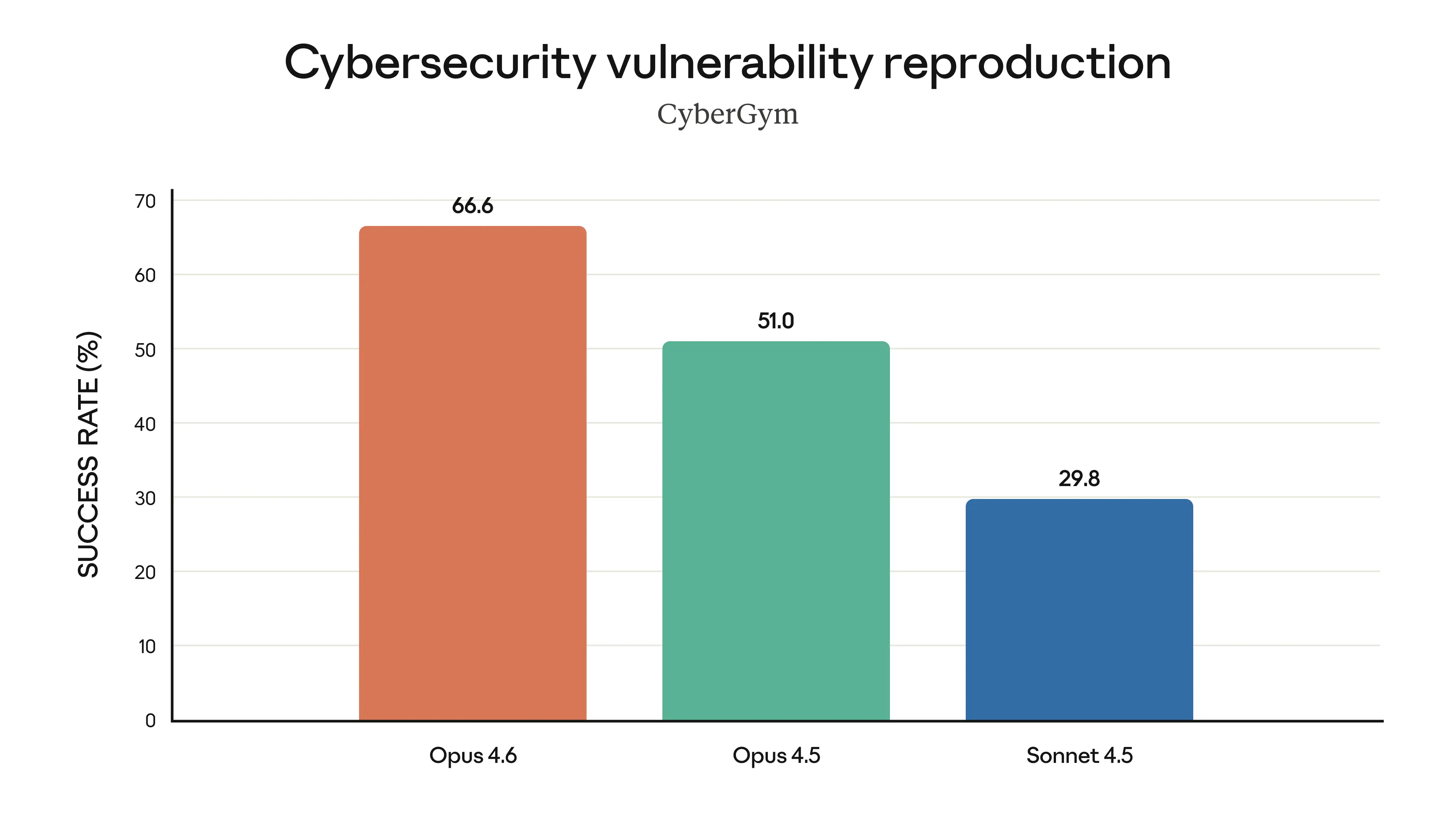 Opus 4.6 finds real vulnerabilities in codebases better than any other model — Source: Anthropic
Opus 4.6 finds real vulnerabilities in codebases better than any other model — Source: Anthropic
Legal (BigLaw Bench by Harvey): 90.2% overall, with 40% perfect scores — exceptional for legal analysis.
Life Sciences: Almost 2× better than Opus 4.5 on computational biology, structural biology, organic chemistry, and phylogenetics.
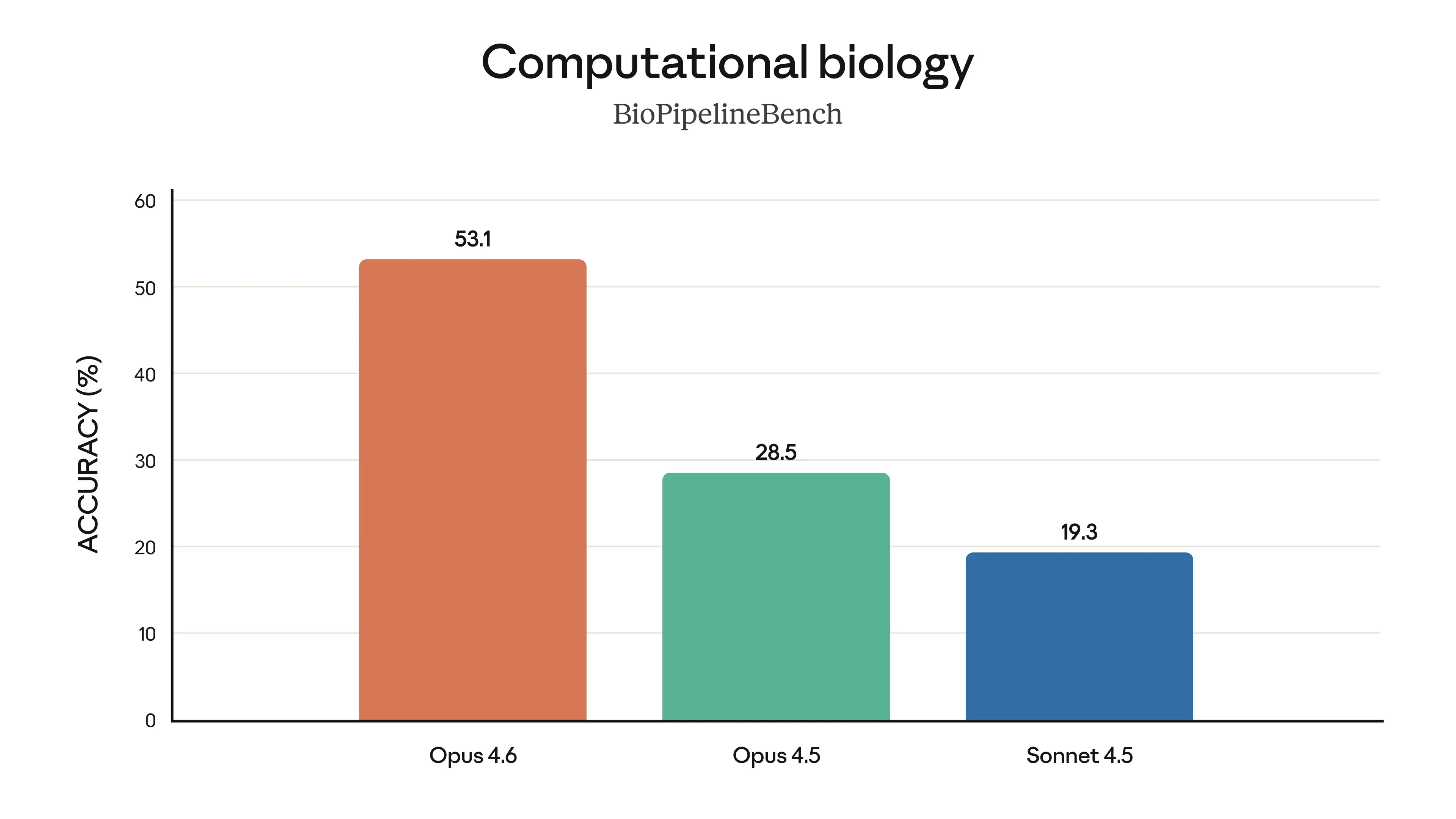 Opus 4.6 performs almost 2× better than Opus 4.5 on computational biology, structural biology, organic chemistry, and phylogenetics — Source: Anthropic
Opus 4.6 performs almost 2× better than Opus 4.5 on computational biology, structural biology, organic chemistry, and phylogenetics — Source: Anthropic
Root Cause Analysis (OpenRCA): Excels at diagnosing complex software failures.
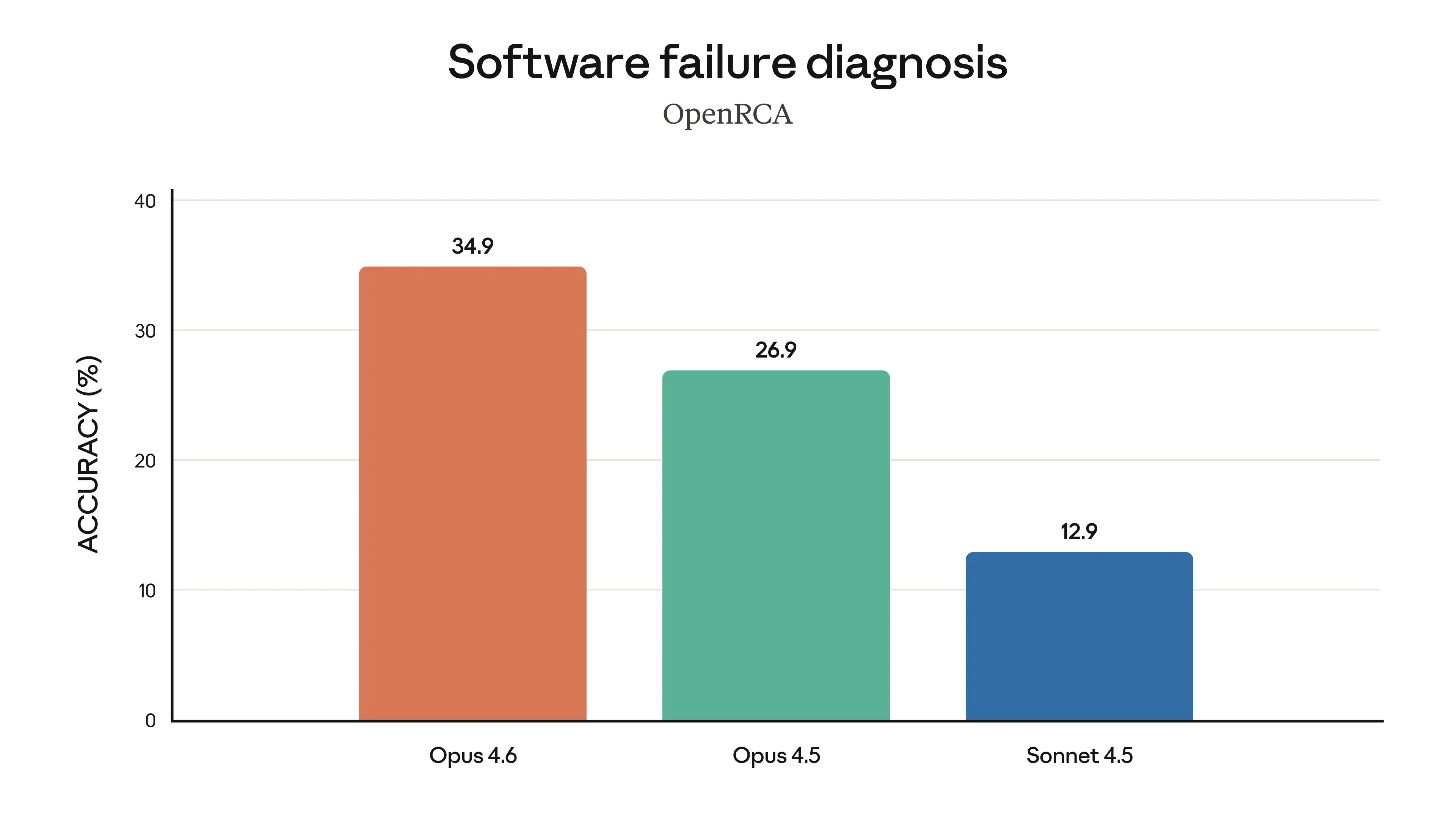 Opus 4.6 excels at diagnosing complex software failures — Source: Anthropic
Opus 4.6 excels at diagnosing complex software failures — Source: Anthropic
Multilingual Coding (SWE-bench): Resolves issues across multiple programming languages.
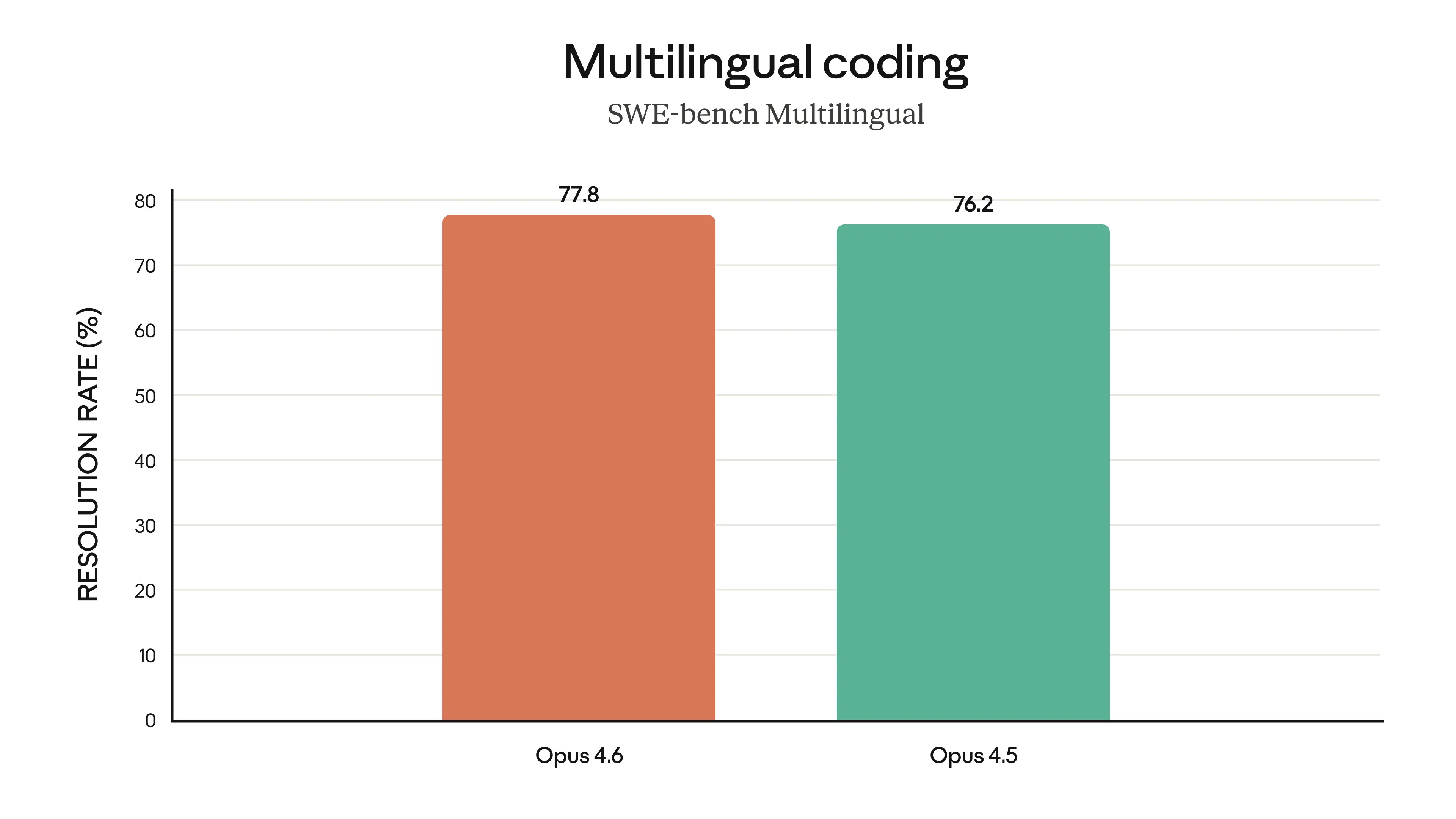 Opus 4.6 resolves software engineering issues across programming languages — Source: Anthropic
Opus 4.6 resolves software engineering issues across programming languages — Source: Anthropic
Long-Term Coherence (Vending-Bench 2): Maintains focus over time, earning $3,050.53 more than Opus 4.5.
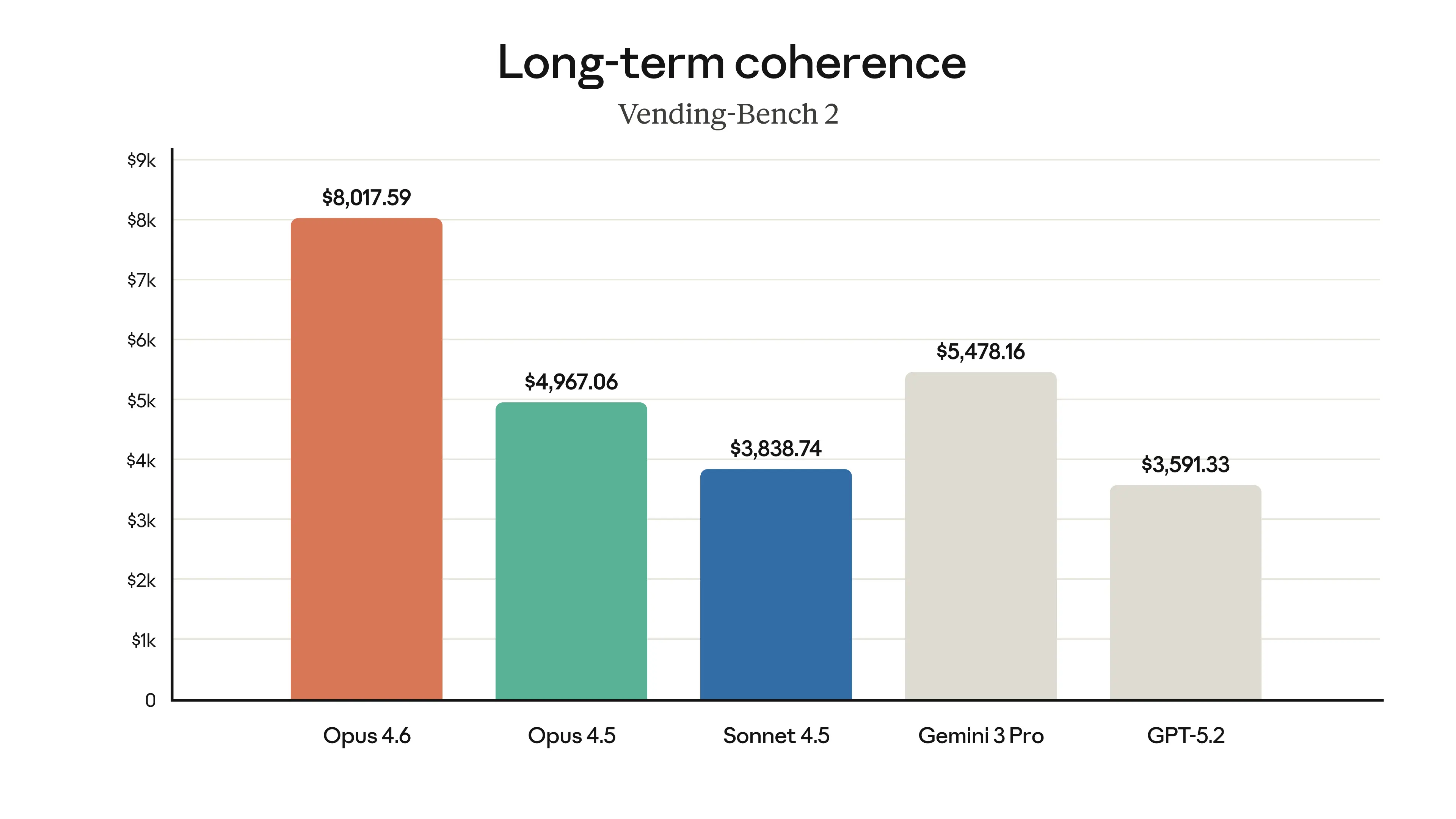 Opus 4.6 maintains focus over time and earns $3,050.53 more than Opus 4.5 on Vending-Bench 2 — Source: Anthropic
Opus 4.6 maintains focus over time and earns $3,050.53 more than Opus 4.5 on Vending-Bench 2 — Source: Anthropic
Key Features Deep Dive
Agentic Coding with Claude Code
Opus 4.6 powers the latest version of Claude Code, Anthropic's coding agent. Key improvements:
More careful planning: Before making changes, Opus 4.6 creates detailed execution plans, reducing errors on large refactoring tasks.
Sustained long tasks: Context compaction means coding sessions can run for hours without context degradation. The model summarizes earlier work to free up context for current operations.
Agent Teams (Research Preview):
User: "Add authentication to this Next.js app with OAuth,
database sessions, and role-based access control."
Claude Code spawns:
→ Agent 1: OAuth provider integration (Google, GitHub)
→ Agent 2: Database schema + session management
→ Agent 3: Middleware + role-based route protection
→ Coordinator: Merges work, resolves conflicts, runs tests
Larger codebase support: With 1M context, Opus 4.6 can understand entire medium-to-large codebases in a single session, maintaining awareness of architectural patterns, naming conventions, and cross-file dependencies.
Knowledge Work & Document Processing
📺 Claude Opus 4.6 in Action
Source: Anthropic YouTube — Claude Opus 4.6 capabilities demo, February 5, 2026.
Opus 4.6 excels at tasks that require synthesizing large volumes of information:
- →Financial analysis: Process quarterly reports, identify trends, generate summaries with specific data points
- →Research synthesis: Analyze hundreds of papers, extract methodologies, compare findings
- →Legal review: Parse contract sets, identify inconsistencies, flag risk clauses (90.2% on BigLaw Bench)
- →Document creation: Generate reports, spreadsheets, and presentations via Claude Cowork
Integration with Claude Cowork
Claude Cowork now runs on Opus 4.6 as its base model (claude-sonnet-4-5-20250929 was previously used). This means:
- →Better file processing: More accurate extraction from PDFs, spreadsheets, and documents
- →Smarter organization: Better understanding of file relationships and content
- →Longer sessions: Context compaction enables multi-hour automation tasks
- →Improved accuracy: Fewer errors on complex multi-step workflows
Claude in Excel & Claude in PowerPoint (New)
Anthropic has made substantial upgrades to Claude in Excel and is releasing Claude in PowerPoint in research preview:
- →Claude in Excel: Handles harder, long-running tasks — can plan before acting, ingest unstructured data and infer the right structure, and handle multi-step changes in one pass
- →Claude in PowerPoint: Reads your layouts, fonts, and slide masters to stay on brand — generates full decks from descriptions or templates. Available for Max, Team, and Enterprise plans
This integration makes Claude a genuine productivity tool for everyday office work, not just a coding assistant.
Pricing & Availability
API Pricing
| Tier | Input | Output |
|---|---|---|
| Standard (≤200K context) | $5 / M tokens | $25 / M tokens |
| 1M Context Beta (>200K) | $10 / M tokens | $37.50 / M tokens |
| US-only Inference | 1.1× standard | 1.1× standard |
Subscription Access
| Plan | Price | Opus 4.6 Access |
|---|---|---|
| Free | $0/mo | ❌ No access |
| Pro | $17-20/mo | ✅ Limited usage |
| Max | $100-200/mo | ✅ Higher limits |
| Enterprise | Custom | ✅ Full access |
Platform Availability
Opus 4.6 is available on all major platforms from day one:
- →claude.ai — Direct web access
- →Anthropic API — Model ID:
claude-opus-4-6 - →AWS Bedrock —
anthropic.claude-opus-4-6-v1 - →Google Vertex AI —
claude-opus-4-6 - →Claude Code — Desktop coding agent
- →Claude Cowork — Desktop automation agent
How to Use Opus 4.6
API Quick Start
import anthropic
client = anthropic.Anthropic()
# Standard usage with adaptive thinking (default)
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=16384,
messages=[
{"role": "user", "content": "Analyze this codebase and suggest architectural improvements."}
]
)
# With explicit max effort for complex tasks
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=16384,
thinking={
"type": "enabled",
"budget_tokens": 120000 # Max effort
},
messages=[
{"role": "user", "content": "Solve this complex mathematical proof..."}
]
)
Best Practices
- →
Let adaptive thinking work: Don't set manual effort levels unless you have a specific reason. The model's adaptive system is highly effective at choosing the right reasoning depth.
- →
Leverage the 1M context: For large codebases or document sets, feed everything into the context rather than summarizing manually. Opus 4.6's 76% MRCR v2 score means it genuinely retains information across the full window.
- →
Use agent teams for parallel work: When your task has independent subtasks, enable agent teams in Claude Code to parallelize the work.
- →
Enable context compaction for long sessions: For tasks running over an hour, enable context compaction to prevent degradation.
- →
Compare with Sonnet for cost optimization: Not every task needs Opus. Use Sonnet 4.5 for routine tasks and reserve Opus 4.6 for complex reasoning, long-context work, and agentic coding.
Use Cases & Recommendations
When to Use Opus 4.6
| Use Case | Why Opus 4.6 | Alternative |
|---|---|---|
| Large codebase refactoring | 1M context + agent teams | Claude Code with Sonnet (smaller projects) |
| Legal document review | 90.2% BigLaw Bench, long context | Manual review (for final verification) |
| Research synthesis (100+ papers) | 1M context, strong retrieval | Gemini (if >1M tokens needed) |
| Cybersecurity investigation | 38/40 blind wins vs 4.5 models | GPT-5.3-Codex (for active exploitation testing) |
| Financial analysis | Deep reasoning + document processing | GPT-5.2 (for visual charts) |
| Complex multi-step automation | Cowork + context compaction | Simpler automation tools (for single-step) |
When NOT to Use Opus 4.6
- →Simple Q&A or chat: Use Sonnet 4.5 or Haiku — faster and cheaper
- →Real-time autocomplete: Use specialized coding models in IDE
- →Image generation: Claude doesn't generate images
- →Tasks under 1K tokens: Overkill — use smaller models
Safety & Alignment
Anthropic reports that Opus 4.6 has the lowest over-refusal rate of any recent Claude model, meaning it's less likely to unnecessarily refuse reasonable requests while maintaining strong safety boundaries.
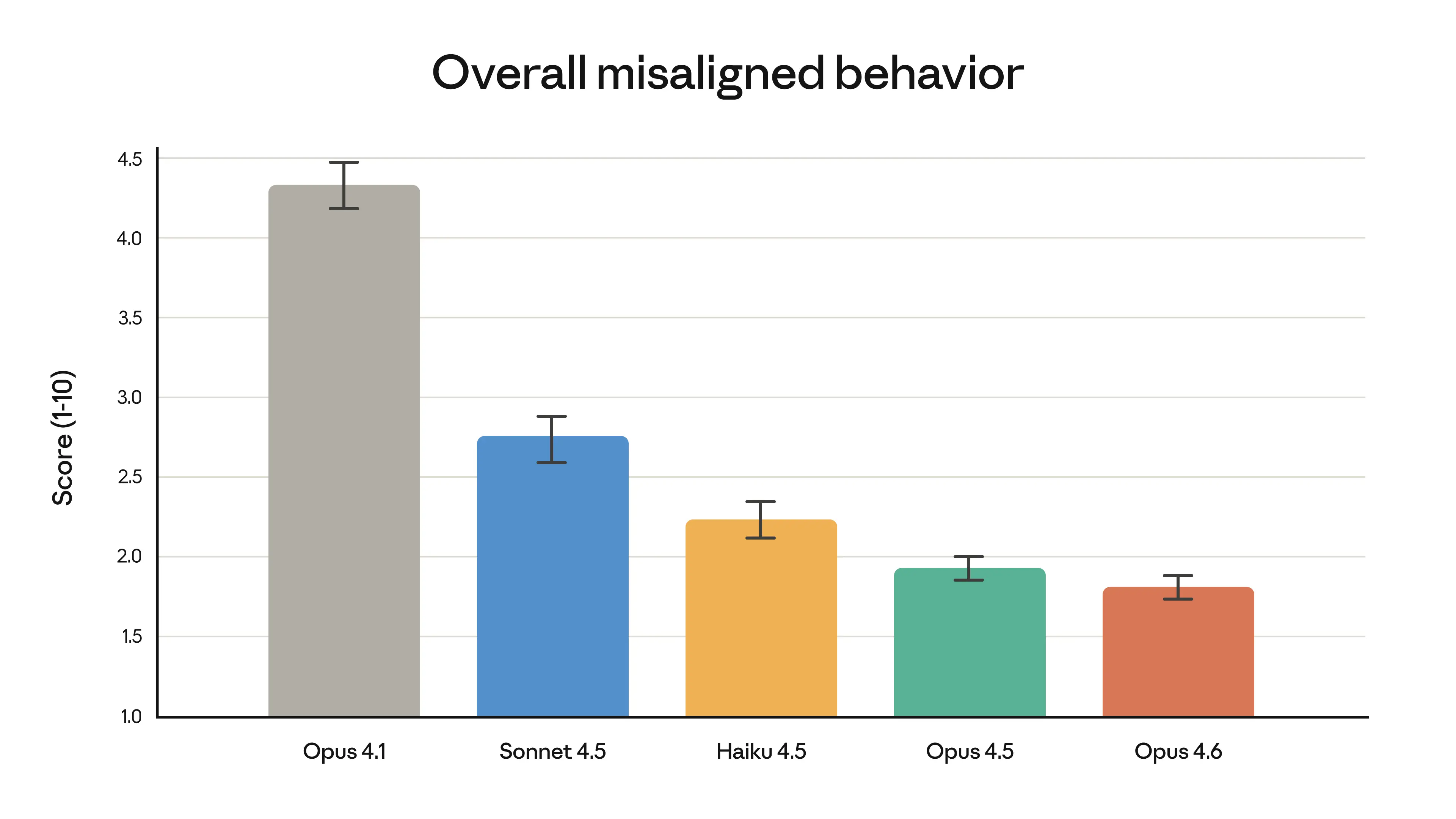 The overall misaligned behavior score for each recent Claude model on Anthropic's automated behavioral audit — Source: Anthropic
The overall misaligned behavior score for each recent Claude model on Anthropic's automated behavioral audit — Source: Anthropic
Key Safety Properties
- →Low deception rate: Minimal instances of misaligned behaviors including sycophancy and delusion
- →Robust alignment: Safety profile equal to or better than any frontier model
- →Comprehensive evaluation: 6 new cybersecurity probes were developed specifically for this release
- →System card published: Full transparency on capabilities and limitations
Safety vs. Previous Models
Opus 4.6 achieves a difficult balance: it is more capable and less restrictive simultaneously. The lower over-refusal rate means fewer false positives (legitimate requests being refused), while the improved safety evaluation means actual harmful requests are still caught.
Early Access Partner Feedback
Major companies have validated Opus 4.6's capabilities with direct testimonials:
"Claude Opus 4.6 is the new frontier on long-running tasks from our internal benchmarks and testing. It's also been highly effective at reviewing code." — Michael Truell, Co-founder & CEO, Cursor
"Claude Opus 4.6 achieved the highest BigLaw Bench score of any Claude model at 90.2%. With 40% perfect scores and 84% above 0.8, it's remarkably capable for legal reasoning." — Niko Grupen, Head of AI Research, Harvey
"Claude Opus 4.6 autonomously closed 13 issues and assigned 12 issues to the right team members in a single day, managing a ~50-person organization across 6 repositories." — Yusuke Kaji, General Manager AI, Rakuten
"Claude Opus 4.6 is an uplift in design quality. It works beautifully with our design systems and it's more autonomous, which is core to Lovable's values." — Fabian Hedin, Co-founder, Lovable
All quotes sourced from Anthropic's official announcement.
Additional partners include: GitHub, Windsurf, NBIM, Notion, Asana, Figma, Shopify, Vercel, Thomson Reuters, Ramp, Box, Cognition (Devin), and Bolt.new.
FAQ
What is the difference between Claude Opus 4.6 and Sonnet 4.5?
Opus 4.6 is Anthropic's most capable model, designed for complex tasks requiring deep reasoning, long-context understanding, and agentic coding. Sonnet 4.5 is faster and cheaper, best suited for routine tasks. Key differences: Opus has 1M context (vs 200K), adaptive thinking, and significantly higher benchmark scores.
Is Claude Opus 4.6 worth the upgrade from 4.5?
Yes, for most professional use cases. The 67% price reduction alone makes it compelling — you get a more capable model for less money. The 1M context window, adaptive thinking, and improved agentic coding make it a substantial upgrade, not an incremental improvement.
How does context compaction work?
When enabled, Opus 4.6 automatically summarizes older parts of the conversation context to free up space for new information. This allows agentic sessions to run for hours without hitting context limits or losing track of the overall task.
Can I use Opus 4.6 in Cursor or other IDEs?
Opus 4.6 is available via the Anthropic API, which means any IDE or tool that supports custom API endpoints can use it. Claude Code (Anthropic's native coding agent) runs Opus 4.6 natively with full agent teams support.
What languages does Opus 4.6 support for coding?
Opus 4.6 supports all major programming languages including Python, JavaScript/TypeScript, Java, C/C++, Rust, Go, Ruby, PHP, Swift, Kotlin, and more. It excels particularly at Python and TypeScript based on benchmark performance.
Related Articles
- →Claude Opus 4.5 Guide — Previous model comparison
- →Claude Opus 4.6 vs GPT-5.3 Codex — Head-to-head comparison
- →GPT-5.3 Codex Guide — OpenAI's new coding model
- →Claude Cowork Guide — Anthropic's desktop agent
- →LLM Benchmarks 2026 — Full model comparison
- →AI Code Editors Comparison — IDE benchmarks
Key Takeaways
- →
Claude Opus 4.6 is Anthropic's most powerful model, released February 5, 2026 with state-of-the-art agentic coding and long-context capabilities
- →
1M token context window (beta) enables working with entire codebases and massive document sets — with 76% MRCR v2 proving genuine information retention
- →
Adaptive thinking eliminates the need to manually set reasoning effort — the model decides when to think deeper
- →
67% price reduction from Opus 4.5 makes frontier capabilities significantly more accessible
- →
Agent teams and context compaction enable multi-hour, parallelized coding sessions in Claude Code
- →
Leading benchmarks: Terminal-Bench 2.0 #1, Humanity's Last Exam #1, BrowseComp 86.8%, BigLaw Bench 90.2%
- →
Available everywhere: API, claude.ai, AWS Bedrock, Google Vertex AI — with full ecosystem integration
Master Advanced Prompt Workflows with AI
Claude Opus 4.6's adaptive thinking and agent teams represent the cutting edge of AI-assisted workflows. Understanding how to structure complex tasks, chain prompts, and orchestrate multi-agent systems will help you get the most out of this model.
In our Module 4 — Chaining & Routing, you'll learn:
- →How to design multi-step prompt workflows
- →Conditional routing based on input complexity
- →Building verification checkpoints for AI-generated output
- →When to use single-model vs. multi-agent approaches
- →Cost optimization across model tiers
→ Explore Module 4: Chaining & Routing
Last Updated: February 6, 2026 Features and specifications verified against Anthropic's official announcement and API documentation.
Module 4 — Chaining & Routing
Build multi-step prompt workflows with conditional logic.